外链爬虫任务引擎
一、概述
核心功能通俗概括:导入一批域名/网址为基础,采集获得更多的域名/网址;给定一个txt文件(种子文件),里面一行一个url(网址)或域名,外链爬虫任务即可批量并发的把文件中的所有URL进行模拟访问,然后收集外链资源(与当前模拟访问的网站非同域名不一样的其他域名链接),类似搜索引擎蜘蛛的原理,属于无限采集。当然,您也可以理解为"友情链接"采集。
MSRAY-PLUS可从用户提供的url种子地址,源源不断的自动爬取全网网站数据(无限爬取),并进行结构化数据存储与自定义过滤处理。
软件还可以自动去除重复记录,以及根据用户启用的过滤器,把需要过滤的数据剔除。之后,软件会实时存储采集结果到文件中,并支持自定义导出excel或者txt文件、自定义导出的字段、自定义导出的数据采集时间范围等。
一个网站,可能存在0个或多个外链域名。为了防止部分网站无外链导致软件内置蜘蛛无内容可爬,建议种子文件的内容大于1万条数据(越多越好,无压力支持导入百万种子数据)。如果种子文件比较大,建议手工复制到主程序目录下的"seed/external_task"目录下。复制后,即可直接在软件界面选择本地文件。
特性:
1. 支持自定义线程数;
2. 支持自动去重复;
3. 支持自定义过滤器规则;
4. 支持自定义存储字段;
5. 支持自定义存储字段、导出字段、导出文件格式;
6. 支持失败自动重试;
7. 支持无限采集;
9. 支持存储进度;
10. 支持实时显示进度、结果数、重复数、被过滤数、执行中任务、已完成任务条数等等;
11. 支持自定义时间(一小时为单位)自动分割采集结果;
12. 支持自定义每次采集的备注信息(可按备注导出结果);
13. 同时支持前端与后端实时查看运行日志。
14. 支持webhook,将采集结果数据实时推送到外部自定义API地址;
15. 支持自定义扩展种子的条件(顶级域名、国内网站、国外网站)。
二、视频一览
测试条件:本测试视频,机器配置:内存为16G,CPU为:i5-11400 @2.60GHZ
三、任务界面说明
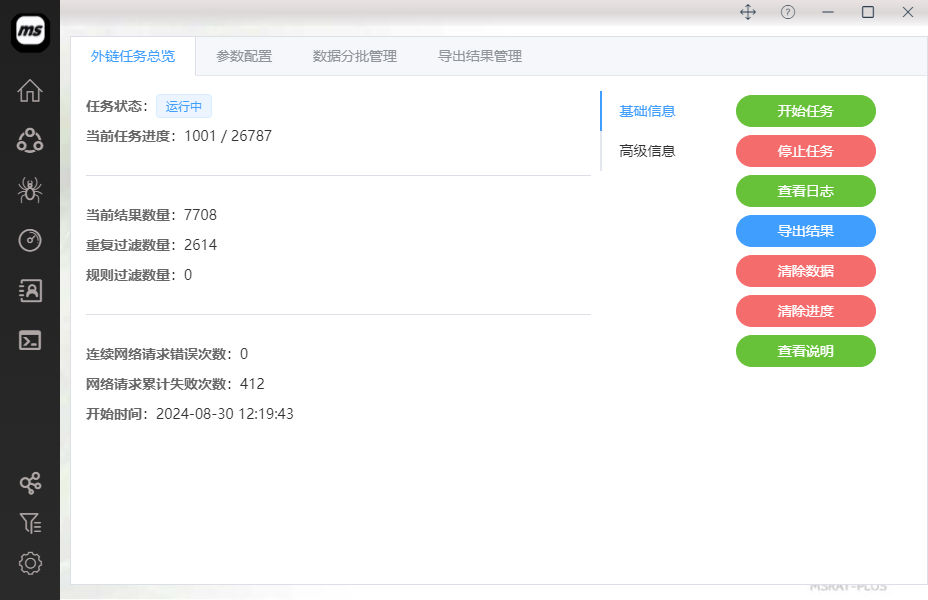
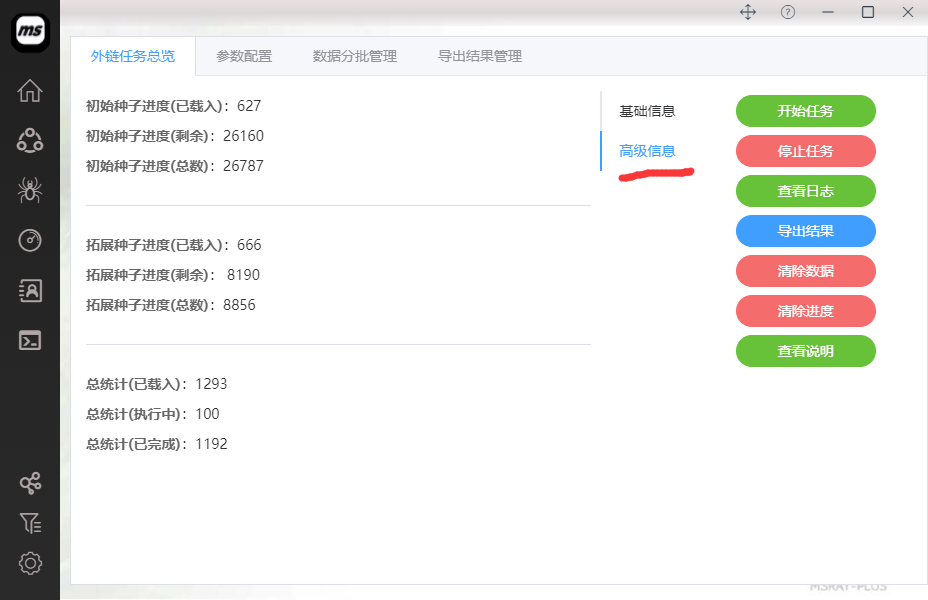
1: 任务数据说明
注意,为了高并发下的效率问题,减少资源占用等,msray-plus相关统计计数采用了缓存方案,不能保证统计数据的百分百准确性。同时,软件强制关闭停止也会影响该数值。
实际的结果数据,其实是会大于界面上显示的结果数据的。
"连续网络请求错误次数",表示的是本次任务执行中,连续出现HTTP访问异常的次数,可用机器网络稳定性预警。当该值较大时,则需要调整降低任务线程数!
"网络请求累计失败次数",表示的是本次任务执行中,共产生了多少次HTTP访问异常。如果该值较大,则代表服务器的综合网络稳定性不好,可调整降低任务线程数!
2: 清除数据按钮说明
在界面的右侧,有个清除数据按钮。功能如下:
1:清除当前引擎任务总采集结果数据;
2:清除当前引擎任务的进度信息(当前选择的种子文件的进度信息);
3:清除当前引擎任务缓存的任务统计数据信息;
特别说明:清除总采集结果数据,不会导致后期采集到重复数据。仅当点击软件首页右下角的“清除总域名数据(重复过滤数据表)”或"清除总网址数据(重复过滤数据表)"才会初始化防重复服务的数据。
四、参数配置说明
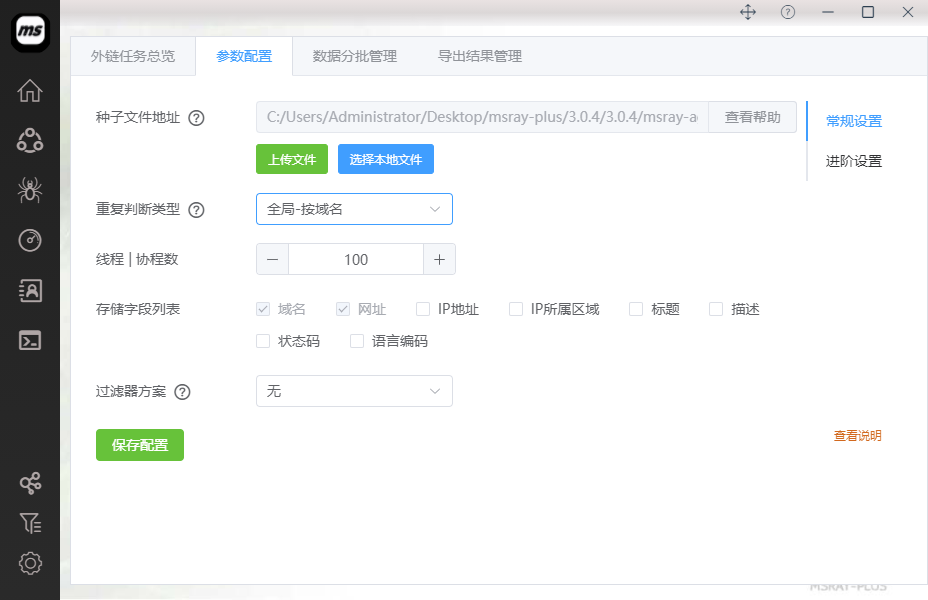
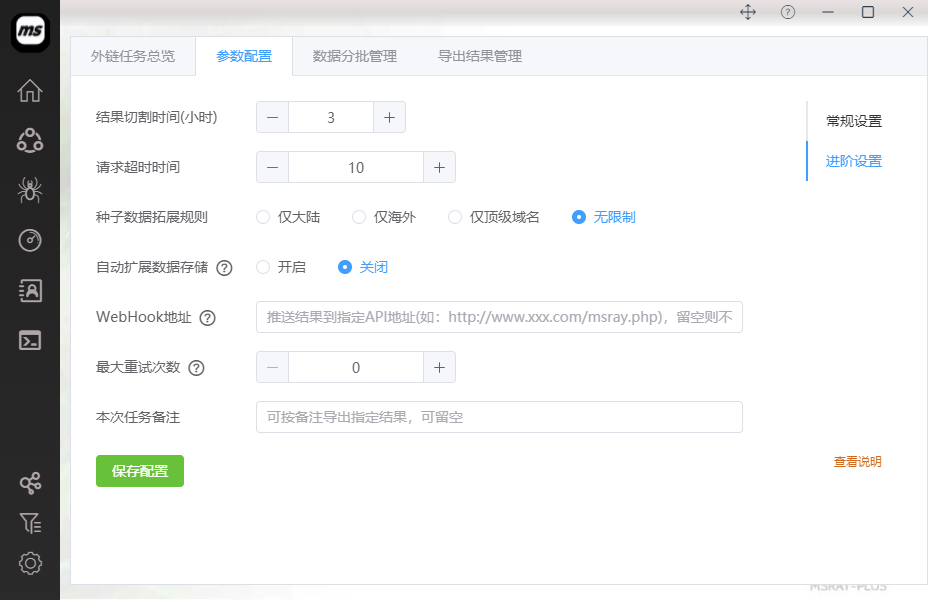
如上图所示,按自己的情况进行配置即可。大部分参数都可以使用默认设置即可。其中,有一些比较重要的设置技巧,下面的内容进行详细说明!
1:[重要]种子文件说明
外链爬虫任务,种子文件的内容格式为:一行一个域名/网址! 注意,是域名或网址,而不是关键词!否则是采集不到任何数据的。
种子文件内容如下例子,也可以打开自带的测试种子文件(位于主程序目录下的seed/exteral_task目录下),参考其内容:
www.xxx.com
http://www.xxx.com
http://www.xxx.com/1.html
可选择上传文件以及选择本地文件两种方案去设置种子文件。分两种情况使用:
1:如果主程序与客户端处于同一台电脑,特别是种子文件比较大的时候,则建议使用"选择本地文件"方案! 具体操作如下:手工把种子文件移动到主程序根目录下的seed/exteral_task 目录下!之后,就可以使用选择本地文件的方法直接选择了!
2:如果主程序与客户端不属于同一个电脑以及或者种子文件比较小,则建议使用"上传文件"方案!
如果是上百兆的大种子文件,建议手工复制到程序对应目录,减少上传失败以及速度慢的问题!
2:[重要]重复判断类型该如何选择?
重复判断类型,分类全局-按域名、全局-按网址、以及单模块-按域名三种。
什么是域名?
www.msray.cn 与 msray.cn、user.msray.cn 都属于域名!
什么是网址?
http://www.msray.cn、https://www.msray.cn、http://www.msray.cn/doc、http://www.msray.cn/xxxx.html 都属于网址!
例子: 比如采集到如下数据:
1: https://www.aaa.com/1.html
2: https://www.aaa.com/x/x.html
3: https://www.aaa.com/1.php?id=x
4: https://www.bbb.com/x/x.html
5: https://www.bbb.com/y
6: https://www.ccc.com/
7: https://www.ddd.net/1.html
1:如果重复判断类型,为"按域名",则:
第1条结果https://www.aaa.com/1.html存储后,第2条、第3条都会被判定为重复,被过滤掉。
第4条结果https://www.bbb.com/x/x.html 存储后,第5条结果会被判定为重复,被过滤掉。
因为,虽然页面URI(网址)不一样,但是域名一样,最多只保留一条!
2:如果重复判断类型,为"按网址",则以上结果都会被保存。因为上述7条结果都是属于不同的网址。除非URI完全一致。
3:“全局按域名”,是软件所有的任务模块的采集结果中都不会出现重复数据,比如在搜索任务引擎中,采集到了xxx.com,那么如果爬虫任务引擎中也采集到了xxx.com就会被过滤掉,不会再次进行存储!
4:而“单模块-按域名”,是仅仅软件的某个引擎内结果不重复。比如选择“单模块-按域名”,则爬虫任务内部的数据不会重复,但是可能与搜索任务引擎中的数据重复。
如果导出结果想要只导出域名,这建议重复判断类型为"按域名"。否则就会导出结果"伪重复"! 因为如果重复判断类型按网址,那么同一个域名的多个不同网址页面的结果确实是不重复的,但导出的只是不重复网址的域名部分,所以看起来像是结果重复,其实这是设置的问题!
3:线程/协程数设置说明
线程/协程数代表的是软件并发执行任务的数量。就像谈对象一样 ,协程数并不是越大越好!适合自己机器配置以及宽带稳定性的并发数量,才是效率最佳的!
为什么呢?因为如果线程数设置的比较大,超出了系统内存或CPU跟不上,可能会导致软件异常。特别是容易导致大面积的网络请求失败超时,反而不如线程小一点,持续稳定运行。
建议设置值范围为:50-500
大家可以打开任务管理器,找到“msray-agent.exe”,观察其资源占用信息。然后做线程数调整。
如果在任务主界面,发现“连续网络请求错误次数”非常多,则建议降低线程数!
4:存储字段说明
如非必要,建议只勾选默认的网址、域名。
开启其他字段,会一定程度的降低采集效率。
如果使用了过滤方案,开启了里面的一些过滤器,则即使不勾选对应的存储字段,必要的字段也会被存储。比如开启了网页标题过滤器,则同时也会获取并存储网页标题!
以下是各个字段对效率影响的评级,评级越高降低的效率则越多:
IP: 中下
IP所属区域:中上
状态码:低
标题:高
描述:高
语言编码:高
5:请求超时时间
如果在任务主界面,发现“连续网络请求错误次数”,或者“网络请求累计失败次数”非常多,则建议增加超时时间数值。建议值的范围为“5-30”。单位为秒
6:过滤方案
在参数配置里面,可以选择是否使用过滤方案。默认为不使用。如果使用,需要先去过滤方案管理界面提前设置好规则!
过滤方案规则的详细说明,可以参考文档《过滤方案与过滤器简介》 以及过滤方案章节下面的其他内容。
同时,我们也整了常用的大量的过滤方案规则,用户可以直接复制导入到软件中使用。具体参考《过滤方案分享》
7:种子数据扩展规则
每次采集数据,都将访问种子数据中的网站,然后提取网站上对应的外部链接地址,然后把不重复的外部链接地址继续放入扩展种子队列,循环往复。如果“种子数据扩展规则”不是“无限制”,则“外部链接”需要满足设定的条件才会继续放入扩展种子队列。
仅国内:仅会将“外部链接”域名对应解析服务器所属区域为中国大陆的数据,继续放入扩展种子队列。
仅海外:仅会将“外部链接”域名对应解析服务器所属区域为非中国大陆的数据,继续放入扩展种子队列。
仅顶级域名:仅会将“外部链接”域名属于顶级域名的数据,继续放入扩展种子队列。
无限制:无任何限制。
8:自动扩展数据存储
如果开启,则会在停止任务后,把剩余未使用的扩展数据追加到种子文件中!
9:WEBHOOK功能与配置说明
WEBHOOK功能接口,可实现采集结果的实时推送服务。每当任务采集到结果,就会自动以http形式发送采集结果的详细信息到设置的WEBHOOK地址,类似于支付接口等系统的异步通知的概念。
根据此接口,我们可以做自定义扩展开发,比如把采集到的数据,存储到数据库中,又或者是自动导入到其他第三方软件中。
详细的数据推送格式与数据接收接口开发例子,请等待上线接口说明文档和DEMO。
10:切割时频说明
结果切割时频的值如果不为0,则软件会对采集结果自动按时间(单位为小时)进行分割。默认结果切割时频的值为1,也就是每小时都将生成一个结果的子文件。
同时,总文件与子文件可同样存在。用户既可以按时间去导出子文件的结果,也可以直接导出总文件的结果!
子文件按时间生成文件名,存储在主程序根目录下的result/search_task目录下。该功能可以防止每次导出结果都是全部数据,也包含了历史已经导出的数据的情况。我们只需要按子文件导出结果即可避免该问题。
同时,您也可以导出结果后,点击任务界面的清除数据按钮,即可清空历史数据。
11:任务备注配置说明
每次启动任务之前,我们可以给当前任务设置一个自定义备注! 启动任务后,每条采集的结果的源数据信息里面, 就会自动包含我们设置的备注信息。与此同时,我们可以在导出选项中,使用"按备注"导出!
该功能可以实现区分每次任务的采集目标,方便导出结果的按备注提取。您可以理解为,备注功能实现了多任务系统的分离。
五、导出结果说明
1:总文件结果导出
点击“外链爬虫任务总览”界面,右侧的“导出结果”按钮,即可导出总文件结果!
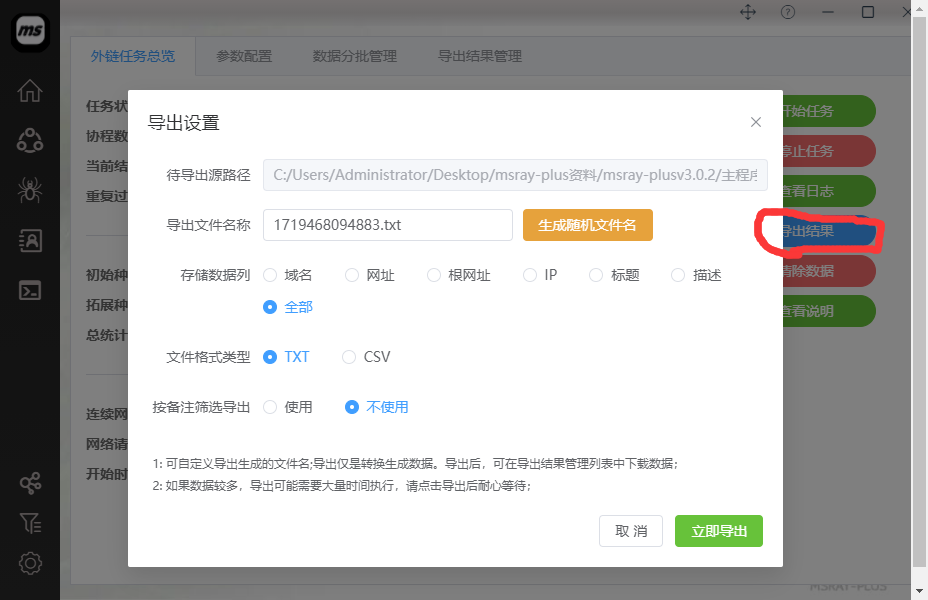
总文件结果导出,就是导出的是外链爬虫任务引擎的全部数据。需要注意的是,每次导出都是当前最新的结果的全部数据,并不会把以前导出的数据剔除。
如果需要每次导出总文件都不包含以前导出过的内容,有以下两个办法:
方案1: 按分批文件导出。前提是设置好分批结果切割时频(默认为1小时一个分批文件)。
方案2: 每次导出后,点击任务界面的“清除数据”按钮。该功能会清除任务的数量统计缓存信息,以及删除引擎的总结果文件!而删除删除引擎的总结果文件之后,下次运行就会重新写入内容,不包含历史数据。
其他说明:如果即想要历史总数据,又不想每次导出包含以前的导出数据,那么您可以手工备份复制主程序根目录下的"result/external_task.txt"文件。与此同时,清除数据按钮并不会删除分批文件,如果忘了手工备份,也可以从分批文件查看数据。
2:分批文件结果导出
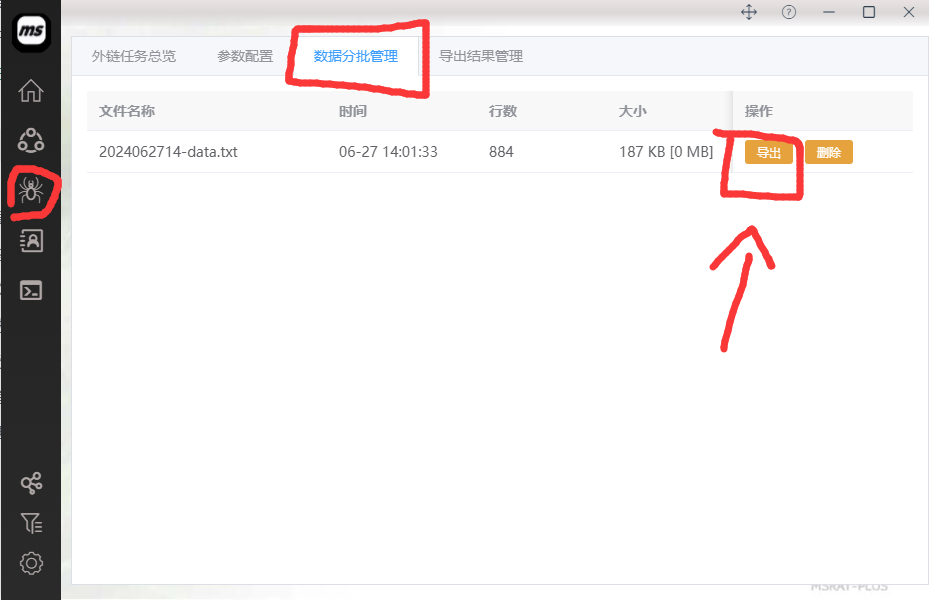
结果切割时频的值如果不为0,则软件会对采集结果自动按时间(单位为小时)进行分割。默认结果切割时频的值为1,也就是每小时都将生成一个结果的子文件。
子文件按时间生成文件名,存储在主程序根目录下的result/external_task目录下。该功能可以防止每次导出结果都是全部数据也包含了历史已经导出的数据的情况。我们只需要按子文件导出结果即可避免该问题。
3:导出设置说明
导出参数设置说明
如果选择域名,则导出的结果文件每行的格式如:www.msray.cn
如果选择根网址,则导出的结果文件每行的格式如:http://www.msray.cn
如果选择网址,则导出的结果文件每行的格式如:http://www.msray.cn/page/1.html
如果选择IP,则导出的结果文件每行的格式如:127.0.0.1
如果选择标题,则导出的结果文件每行都是一个网站的标题内容;
如果选择全部,那么导出的结果中,包含所有以上字段的内容,比如域名、根网址、网址、IP、ip所属国家、标题、描述等;
一般选择txt。同时支持TXT、CSV格式。
按备注导出:可以填写任务备注导出对应的任务结果(需要创建任务的时候填写备注)