联系信息采集任务引擎
一、概述
核心功能通俗概括:导入一批域名/网址为基础,采集获得网页上的联系方式信息并格式化存储;给定一个txt文件(种子文件),里面一行一个url(网址)或域名,联系信息采集任务即可批量并发的把文件中的所有URL进行模拟访问,然后收集每个网站上的联系方式信息。包括但不限于邮箱、手机号、电话号码、QQ、微信、twitter、facebook、whatsapp、whatsapp群组、telegram等。
同时,软件也可以抓取站点域名的whois信息,如何该域名的whois里面存在联系信息,也会被抓取存储!
软件还可以自动去除重复记录。会实时存储采集结果到文件。并支持自定义导出excel或者txt文件、自定义导出的字段、自定义导出的数据采集时间范围等。
同时,软件界面上也会实时显示进度,以及每个联系信息比如邮箱的数量信息。
每个网站,可能存在0个或多个联系方式信息,比如有多个邮箱,则msray-plus会以"|"为分割符,存储所有抓取到的邮箱数据,可导出全部,为了兼容外部软件格式,也支持仅导出第一条邮箱。
如果种子文件比较大,建议手工复制到主程序目录下的"seed/contact_task"目录下。复制后,即可直接在软件界面选择本地文件。
软件不会抓取每个网站的所有页面,仅抓取种子文件中的原始数据URL页面、网站首页、以及其他智能分析出大概率存在联系信息的页面(比如关于我们、联系我们等等)进行抓取。
特性:
1. 支持自定义线程数;
2. 支持自动去除重复数据,比如有2个网站的联系邮箱都是123@qq.com,那么该邮箱仅会存储一次;
3. 支持自定义存储字段、导出字段、导出文件格式;
4. 支持失败自动重试;
5. 支持存储进度;
6. 支持实时显示进度、结果数、执行中任务、已完成任务条数等等;
7. 支持自定义时间(一小时为单位)自动分割采集结果;
8. 支持自定义每次采集的备注信息(可按备注导出结果);
9. 同时支持前端与后端实时查看运行日志。
10 支持webhook,将采集结果数据实时推送到外部自定义API地址;
二、视频一览
测试条件:本测试视频,机器配置:内存为16G,CPU为:i5-11400 @2.60GHZ
三、任务界面说明
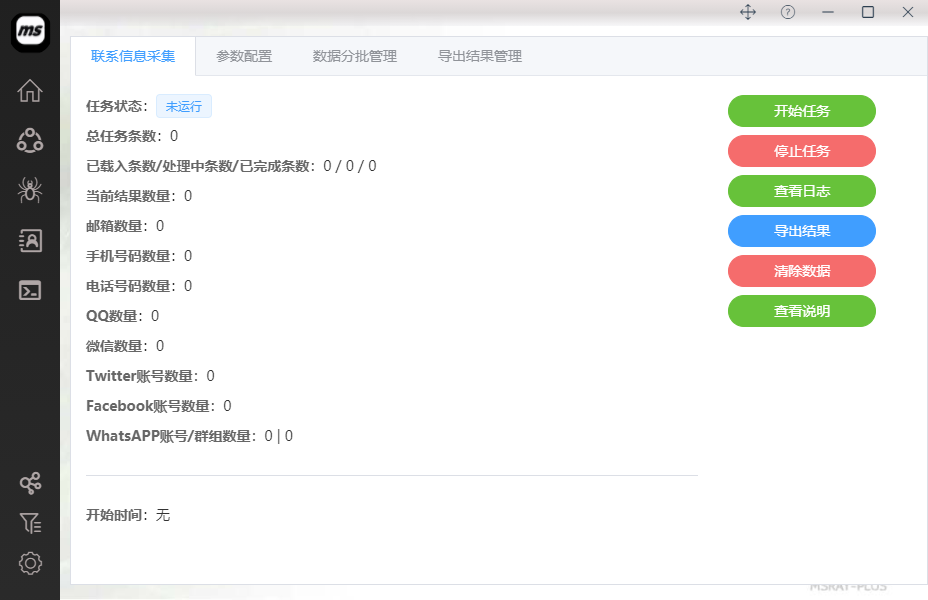
四、参数配置说明
1:参数配置界面
可按需勾选需要存储的字段。比如仅勾选“邮箱”。
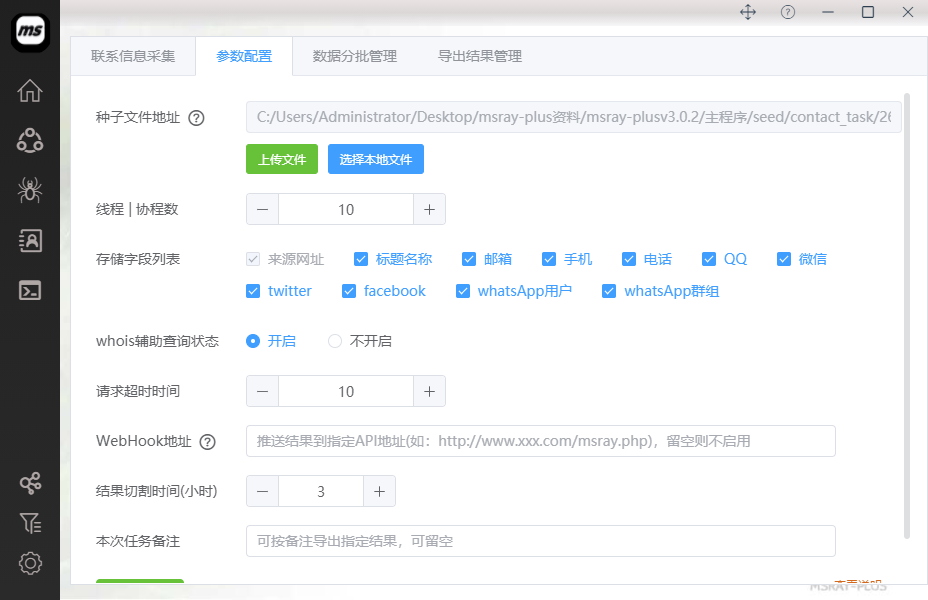
如上图所示,按自己的情况进行配置即可。大部分参数都可以使用默认设置即可。其中,有一些比较重要的设置技巧,下面的内容进行详细说明!
2:[重要]种子文件说明
联系信息采集任务,种子文件的内容格式为:一行一个域名/网址! 注意,是域名或网址,而不是关键词!否则是采集不到任何数据的。
种子文件内容如下例子,也可以打开自带的测试种子文件(位于主程序目录下的seed/contact_task目录下),参考其内容:
www.xxx.com
http://www.xxx.com
http://www.xxx.com/1.html
http://www.xxx.com/news/article1.php?xxx=xxx
可选择上传文件以及选择本地文件两种方案去设置种子文件。分两种情况使用:
1:如果主程序与客户端处于同一台电脑,特别是种子文件比较大的时候,则建议使用"选择本地文件"方案! 具体操作如下:手工把种子文件移动到主程序根目录下的seed/contact_task 目录下!之后,就可以使用选择本地文件的方法直接选择了!
2:如果主程序与客户端不属于同一个电脑以及或者种子文件比较小,则建议使用"上传文件"方案!
如果是上百兆的大种子文件,建议手工复制到程序对应目录,减少上传失败以及速度慢的问题!
3:线程数/协程数设置
线程/协程数代表的是软件并发执行任务的数量。就像谈对象一样 ,协程数并不是越大越好!适合自己机器配置以及宽带稳定性的并发数量,才是效率最佳的!
为什么呢?因为如果线程数设置的比较大,超出了系统内存或CPU跟不上,可能会导致软件异常。特别是容易导致大面积的网络请求失败超时,反而不如线程小一点,持续稳定运行。
建议设置值范围为:50-500
大家可以打开任务管理器,找到“msray-agent.exe”,观察其资源占用信息。然后做线程数调整。
4:whois查询辅助说明
whois(读作“Who is”,非缩写)是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)。通过whois来实现对域名信息的查询。
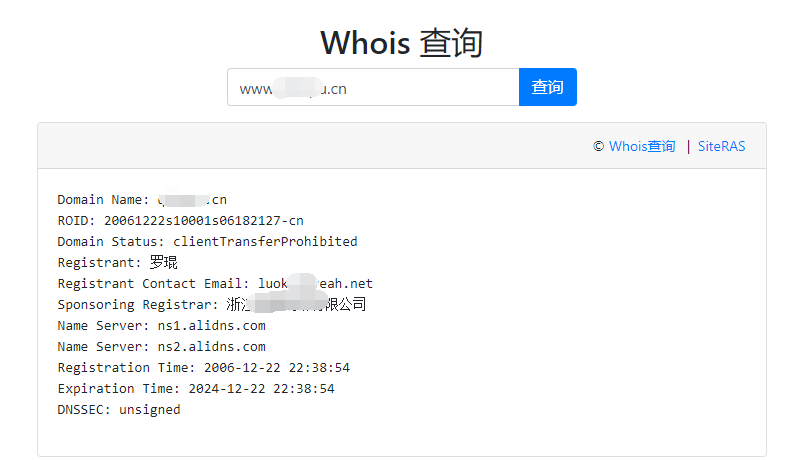
如图所属,whois信息中,可能包含联系人邮箱、电话等信息。
5:超时时间设置
如果网络不稳定,建议增加超时时间数值。建议值的范围为“5-30”。单位为秒
6:webhook地址设置
WEBHOOK功能接口,可实现采集结果的实时推送服务。每当任务采集到结果,就会自动以http形式发送采集结果的详细信息到设置的WEBHOOK地址,类似于支付接口等系统的异步通知的概念。
根据此接口,我们可以做自定义扩展开发,比如把采集到的数据,存储到数据库中,又或者是自动导入到其他第三方软件中。
详细的数据推送格式与数据接收接口开发例子,请等待上线接口说明文档和DEMO。
7:结果切割时间说明
结果切割时频的值如果不为0,则软件会对采集结果自动按时间(单位为小时)进行分割。默认结果切割时频的值为1,也就是每小时都将生成一个结果的子文件。
同时,总文件与子文件可同样存在。用户既可以按时间去导出子文件的结果,也可以直接导出总文件的结果!
子文件按时间生成文件名,存储在主程序根目录下的result/search_task目录下。该功能可以防止每次导出结果都是全部数据,也包含了历史已经导出的数据的情况。我们只需要按子文件导出结果即可避免该问题。
同时,您也可以导出结果后,点击任务界面的清除数据按钮,即可清空历史数据。
8:任务备注配置说明
每次启动任务之前,我们可以给当前任务设置一个自定义备注! 启动任务后,每条采集的结果的源数据信息里面, 就会自动包含我们设置的备注信息。与此同时,我们可以在导出选项中,使用"按备注"导出!
该功能可以实现区分每次任务的采集目标,方便导出结果的按备注提取。您可以理解为,备注功能实现了多任务系统的分离。
五、导出结果说明
1:总文件结果导出
在“联系信息采集”界面,点击右侧的“导出结果”按钮,即可导出总文件结果!
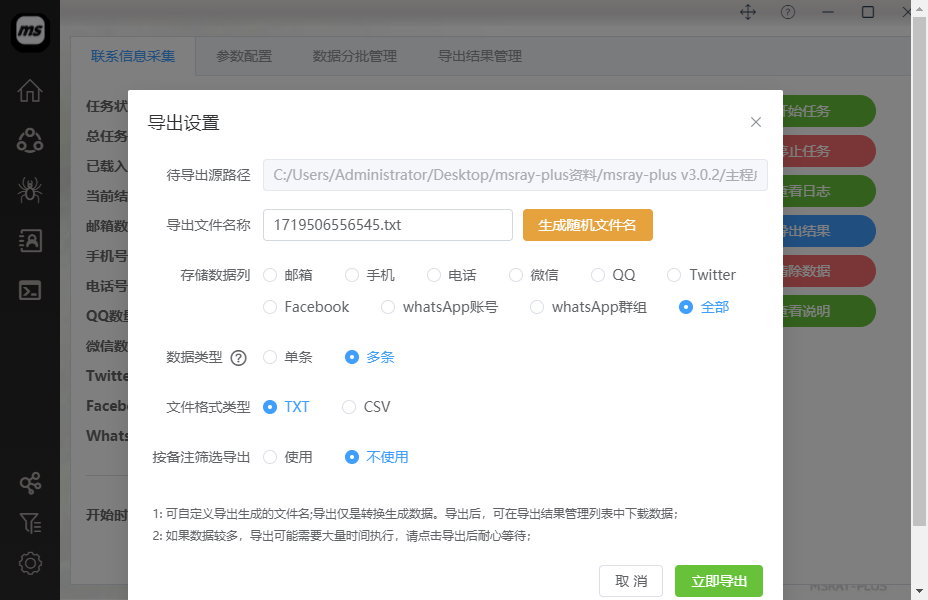
总文件结果导出,就是导出的是任务引的全部数据。需要注意的是,每次导出都是当前最新的结果的全部数据,并不会把以前导出的数据剔除。
如果需要每次导出总文件都不包含以前导出过的内容,有以下两个办法:
方案1: 按分批文件导出。前提是设置好分批结果切割时频(默认为1小时一个分批文件)。
方案2: 每次导出后,点击任务界面的“清除数据”按钮。该功能会清除任务的数量统计缓存信息,以及删除引擎的总结果文件!而删除删除引擎的总结果文件之后,下次运行就会重新写入内容,不包含历史数据。
其他说明:如果即想要历史总数据,又不想每次导出包含以前的导出数据,那么您可以手工备份复制主程序根目录下的"result/contact_task.txt"文件。与此同时,清除数据按钮并不会删除分批文件,如果忘了手工备份,也可以从分批文件查看数据。
2:分批文件结果导出
结果切割时频的值如果不为0,则软件会对采集结果自动按时间(单位为小时)进行分割。默认结果切割时频的值为1,也就是每小时都将生成一个结果的子文件。
子文件按时间生成文件名,存储在主程序根目录下的result/contact_task目录下。该功能可以防止每次导出结果都是全部数据也包含了历史已经导出的数据的情况。我们只需要按子文件导出结果即可避免该问题。
3:导出设置说明
导出参数设置说明
按需选择即可,也可以选择全部。
单条:如果有多个数据,比如一个网站上存在多个邮箱,则仅导出第一条。
多条:如果有多个数据,比如一个网站上有多个邮箱,那么会以“|”为分隔符,导出所有的邮箱。
一般选择txt。同时支持TXT、CSV格式。
按备注导出:可以填写任务备注导出对应的任务结果(需要创建任务的时候填写备注)