网站内容HTML源码过滤器
概述
什么是网站HTML源码?
网页前端代码就是由HTML代码与JS脚本,css样式库文件等组成,HTML代码中包含了核心的内容,比如文本内容。我们可以在谷歌浏览器中打开网页然后单击鼠标右键,选择"查看网页源代码"按钮获取HTML代码。
运用场景
-
需求:要求仅存储,网页内容中包含"女装、童装、男装"的网站数据,又或者存存储网页内容中不包括"新闻"的网站数据;
-
需求:要求仅存储使用某个开源CMS程序的网站(设置该CMS程序的特征做判断);
-
需求:想要采集网页内容中,包含"生态板"或"多层板"这几个文字的网站,精确抓取行业相关网站。
-
需求:想要采集网页中,包含特征"独立站","shopify"等字符的网页,获取跨境电商行业相关数据。
界面
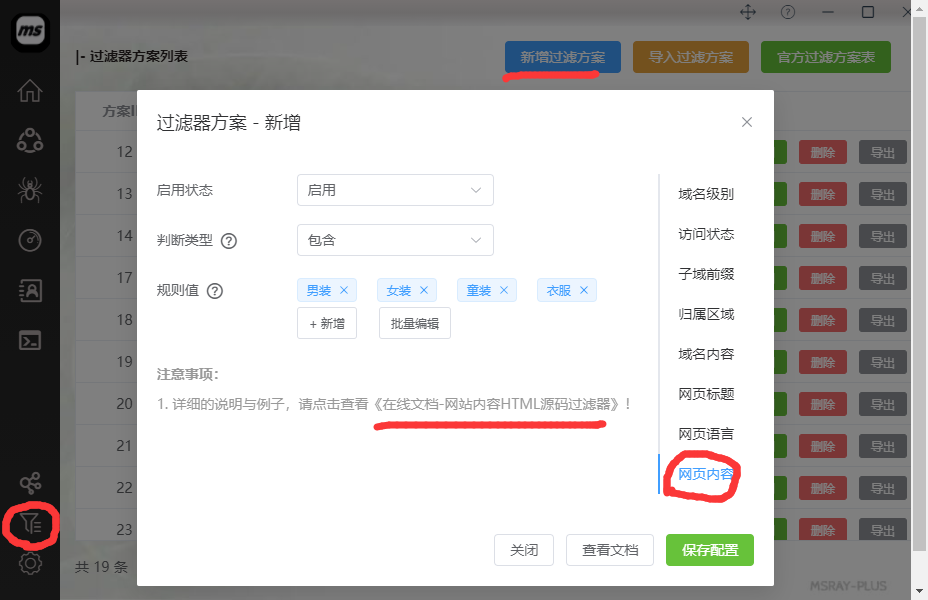
3.0.4版本后,过滤器已经不是独立存在了,已经集成到了过滤方案中,所以我们可以在过滤方案中配置。 功能导航: 软件菜单-》【过滤规则配置】-》【新增过滤方案】-》【网页内容】,如图:
使用建议
如非必要,不建议使用任何过滤器。开启过滤器将针对每个结果进行判断操作,消耗更多的时间从而影响效率!当前过滤器对效率的影响程度为:高
启用与配置说明
过滤器的判断类型分为【包含】以及【不含】:
如果为"包含",则只存储结果数据中,网页HTML源代码中存在【规则值】中任意一项内容的结果;
如果为"不含",则网页HTML源代码中包含【规则值】中任意一项的内容的数据都不会被存储!
规则值需要自行添加配置。可以一个或者多个。点击新增,然后输入需要的值,然后回车键或者点击空白地方实现添加,然后点击保存按钮即可保存配置!
备注:创建了过滤器后,就可以在任务引擎参数配置中,指定选择使用我们创建的过滤方案了。
示例
本次以只采集网页源代码中包含特征"独立站","shopify"等字符的网页,获取跨境电商行业相关数据。
判断类型: 包含
规则值: "独立站" 与 "shopify"
别忘了点击“保存”按钮!